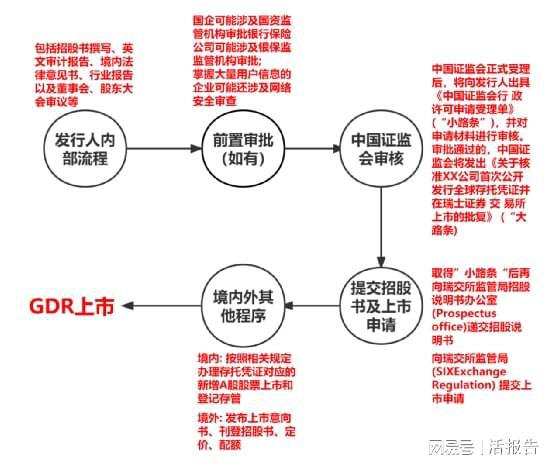
在金融業務流程外包(BPO)領域,知識密集型工作的效率與準確性至關重要。構建一個小型、聚焦的金融知識圖譜(Knowledge Graph),能夠將分散、非結構化的金融信息(如產品條款、監管規則、客戶畫像、市場數據)轉化為結構化、可關聯、可推理的知識網絡,從而顯著提升外包服務的自動化水平、決策支持能力和風險控制精度。以下是針對金融知識流程外包場景的小型知識圖譜構建流程示范。
第一階段:需求分析與范圍界定
- 明確業務場景:需與外包服務需求方(如銀行、保險公司、投資機構)深度溝通,確定知識圖譜的具體應用場景。例如:是用于智能客服(快速準確回答客戶關于理財產品、貸款條件的問題),還是用于合規審查(自動核查交易是否符合內外部法規),或是用于反欺詐(識別異常交易模式與關聯實體)。
- 界定知識范圍:基于場景,劃定核心知識邊界。對于一個小型圖譜,切忌求大求全。例如,若聚焦“消費信貸審批流程外包”,核心知識范圍可限定于:信貸產品類型、申請資格條件、個人征信指標、收入證明標準、相關金融法規(如消費者保護法)、黑名單實體等。
- 設定成功指標:定義可衡量的目標,如問答準確率提升百分比、合規檢查時間縮短量、人工復核工作量減少比例等。
第二階段:知識獲取與數據準備
- 多源數據采集:
- 內部結構化數據:從客戶系統中獲取產品數據庫、客戶關系管理(CRM)數據、歷史交易記錄等。
- 內部非結構化文檔:收集產品說明書、合同模板、內部合規手冊、業務操作流程文檔等。
- 外部公開數據:爬取或接入監管機構發布的法規條文、行業報告、上市公司公告、宏觀經濟指標等。
- 數據清洗與預處理:對非結構化文本進行清洗(去噪聲、標準化格式),并利用自然語言處理(NLP)技術進行關鍵信息抽取,如命名實體識別(NER)提取公司名、人名、金融產品名、金額、日期等;關系抽取識別“屬于”、“違反”、“關聯于”等關系。
第三階段:知識建模與圖譜構建
- 設計本體(Ontology):這是知識圖譜的“骨架”,定義核心概念(實體類型)、屬性及概念間的關系。以信貸場景為例:
- 實體類型:
信貸產品、申請人、金融機構、征信機構、法規條款。
- 屬性:
信貸產品具有“利率”、“期限”、“最高額度”;申請人具有“年齡”、“職業”、“信用評分”。
- 關系:
申請人--【申請】-->信貸產品;信貸產品--【受約束于】-->法規條款;申請人--【有記錄于】-->征信機構。
- 知識抽取與填充:將第二階段處理好的數據,依據定義好的本體,抽取出具體的實體、屬性和關系三元組(頭實體,關系,尾實體)。例如:(
張三,申請,“隨心貸”產品);(“隨心貸”產品,最低信用評分要求,650)。 - 知識存儲:將三元組數據存入專用的圖數據庫(如Neo4j, Nebula Graph),這類數據庫擅長高效處理關聯查詢。至此,一個初步的小型知識圖譜即構建完成。
第四階段:知識融合、推理與應用開發
- 知識融合與質檢:解決不同來源數據的沖突與重復問題(如統一“央行”和“中國人民銀行”指代同一實體)。進行人工抽樣質檢,確保核心知識的準確性。
- 知識推理:利用圖譜的關聯性實現簡單推理。例如,規則“IF 申請人信用評分 < 某產品最低要求 THEN 不符合申請資格”可被編碼并自動觸發。
- 應用層開發:構建面向業務流程外包人員的應用接口:
- 智能查詢界面:支持自然語言或表單式查詢,如“查詢信用評分低于600的申請人可以申請哪些產品?”
- 合規輔助工具:在新業務錄入時,自動關聯并高亮顯示相關法規條款。
- 可視化關聯分析:展示可疑申請人背后的關聯企業網絡,輔助反欺詐分析。
第五階段:部署、維護與迭代
- 系統集成與部署:將知識圖譜系統與外包業務平臺(如工單系統、審批流系統)集成,實現流程嵌入。
- 持續運維與更新:建立知識更新機制。對于動態知識(如利率變動、法規更新),設置定期或觸發式更新流程。監控系統性能與使用反饋。
- 迭代優化:根據業務變化和前期設定的成功指標,擴展知識范圍、優化本體模型、提升應用功能。
對金融知識流程外包的價值
通過上述流程構建的小型金融知識圖譜,能夠將外包團隊從繁重的信息檢索、規則記憶和簡單判斷工作中解放出來,使其更專注于需要復雜判斷和人際溝通的高價值任務。它標準化了知識交付物,降低了因人員流動導致的知識流失風險,確保了跨地域、跨團隊外包服務的一致性與高質量,最終幫助發包方和接包方共同實現降本、增效、風控強化的核心目標。